2023年10月13日,MBA“领域大数据系列讲座”邀请到数据堂的创始人、CEO齐红威分享“人工智能数据要素建设与服务”。讲座由经管学院副院长田英杰教授主持。
齐红威曾担任NEC中国研究院智能信息处理研究部部长、高级研究员。目前作为数据堂的创始人、CEO,主要专注人工智能数据服务、联邦数据与联邦服务。本次讲座围绕“智能数据”分八个部分展开介绍,分别是“智能数据要素”“智能数据要素产业发展的状况”“智能数据应用场景”“影响人工智能成功的因素”“智能数据生产与处理”“联邦模式”“人工智能技术评测解决方案”和“大模型数据处理及私有化训练”。

智能数据要素
齐红威称,PC时代把人和内容联系起来, Web2时代也即是我们正在经历的移动时代。未来社会是虚拟和现实并存的社会,即元宇宙,也可以称为Web3。Web3的技术支撑是区块链,操作系统是ChatGPT。未来人工智能的趋势是:通用领域+垂直领域的大模型服务构成未来元宇宙。元宇宙和数字经济的本质是相同的。数据要素是应用发展的基础材料和核心要素。人工智能背后的核心逻辑是数据、算力和算法,其中数据是人工智能的原材料,而人工智能则是推进元宇宙的核心发动机。
智能数据要素产业发展的状况
2014年国务院发布的促进大数据发展行动纲要,全面推进我国大数据发展和应用。我国数据产业发展的概况是:第一轮已过,第二轮正在经历,第三轮已经显现。第一轮大数据主要应用于征信风控、精准营销,以及政务决策等领域。数据要素是个人隐私数据,技术特点是用户画像、大规模统计分析为核心处理技术,个人隐私数据和政务数据基本都是结构化数据。第一轮以数据汇聚的模式来进行数据交易,数据流动带来了安全问题。第二轮是大数据驱动数字经济,这既是全球趋势,也是国家发展的战略方向。习近平总书记指出,支持北京打造国家服务业扩大开发综合示范区,加大先行先试力度,探索更多可复制可推广经验。第二轮特点是产业智能化提升或转型升级为应用目标。核心是发展数字经济,促进内循环,产业数字化,数字产业化。数据特点是业务场景数据为图像、语音、视频、文本格式等非结构化数据。技术特点是人工智能为核心处理技术,非结构化数据需要人工智能技术智能处理、识别、判断。第三轮使用数据分布式的模式来进行数据服务,采用数据不动、算法模型动的数据服务模式。
智能数据应用场景
齐红威介绍了自动驾驶、智能客服、自动检修以及医疗等智能数据应用场景。自动驾驶的视频案例生动形象地展现出自动驾驶背后的技术逻辑。通过对自动驾驶数据的收集、处理、标识和应用,展示了人工智能技术的应用前景。智能客服案例介绍了语音识别人工智能的技术,通过大量数据标注和模型训练,使得能够准确识别出来用户语音,做到模拟真人语音生成和声纹识别。数据标注和模型训练也使得人脸识别技术更为精准。自动检修包括铁路检修、残次品检修、外观缺陷检测等。以前人工检修成本很高,现在可以通过人工智能的方式,通过图片、视频识别故障,提高故障识别率,降低维修成本。医疗领域也是大数据技术应用率很高的场景,需要对很复杂的医学影片进行标注,提高医疗诊断的精度和效率。
影响人工智能成功的因素
首先,数据采集和标注的质量从根本上决定了算法的识别精度,算法识别精度一般不会高于训练数据精度。以人脸识别为例,前期对人脸识别的标注只有一个框,后来可以标注五官等关键点,到现在全脸要标注256个点,要对短视频的动态美颜,甚至做到标注每个发丝。其次,算法迁移后新场景数据的学习也是影响人工智能能否成功的重要因素。人工智能算法的跨场景的自适应性不够。第三,智能应用需要训练数据规模足够大。同样的数据在不同的规模效果实现不同。第四是数据孤岛问题,数据的联通与共享也影响人工智能的应用。
智能数据生产与处理
人工智能数据的获取是从数据的采集开始,依次进行数据标注、数据训练、形成模型和生产。智能数据生产与处理核心点是如何快速获取大量的数据,众包是现在切实可行、成本最低的一种方式,它的覆盖场景很丰富。
联邦模式
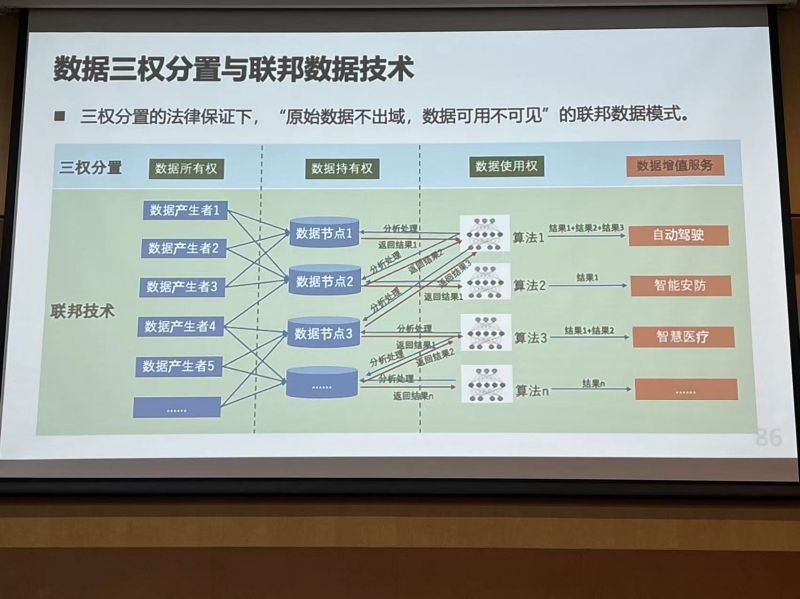
联邦数据作为一种新的数据服务范式,可以使各方在不披露原始数据的情况下建立联邦共享。联邦模式通过对数据所有权、数据持有权和数据使用权三权分置,实现“原始数据不出域,数据可用不可见”。联邦模式的本质是对数据的利用,联邦数据的原理是去获取这些不动的数据、算法或模型对数据进行分析,得到有价值的结果。这样既满足安全隐私要求,又满足用户隐私保护和数据安全。
人工智能技术评测解决方案
人工智能技术评测解决方案可以解决人工智能应用功能、性能、实现和安全等问题。传统的方案可以评估软件功能,但无法评估模型。但模型在人工智能应用中非常重要,所以需要一整套的评测逻辑。模型的评测方案为评测工具、评测标准、评测用例组成的评测流程,以获取评测结果。要对评测对象先制定评测标准和评测方案,对于不同领域如图像、文本、语音类的领域分别有不同的评测方案,结合评测标准和评测方案制定评测工具,最后得出评测结果。评测方案的难点在于大量的评测标准制定。

大模型数据处理及私有化训练
人工智能技术出现之前,存储在数据库中的数据基本上都是结构化的数据。但是随着音频、视频、图片成为目前互联网的主流,采用大模型transformer的神经网络形式,将大量非结构化的知识库存储到模型的每个节点,将神经网络的各个节点打通,就如同人脑一样,将所有知识串联起来。大模型服务成本远低于人工成本,是未来的发展趋势。因此,在垂直行业,私有化领域大数据治理及模型生成工具链势在必行。
齐红威最后总结到,大模型的背后都是人的工作,大模型的光鲜亮丽需要大量人员进行标注、分析和算法研究,人还是最关键的因素。
(文、图/何燕贤 王茜)
编辑 冯芳 审核 王海娟